

2024-09-18
python2.7安装mysql-python 报错没找到my_config.h
解决办法: 创建my_config.h文件 vim /usr/include/my_config.h1添加my_config.h内容 链接: 官网
逆水行舟, 不进则退!
解决办法: 创建my_config.h文件 vim /usr/include/my_config.h1添加my_config.h内容 链接: 官网
安装 Python 3.10:前往 Python 官网(https://www.python.org/downloads/windows/)下载并安装 Python 3.10。 安装 Nuitka:在...
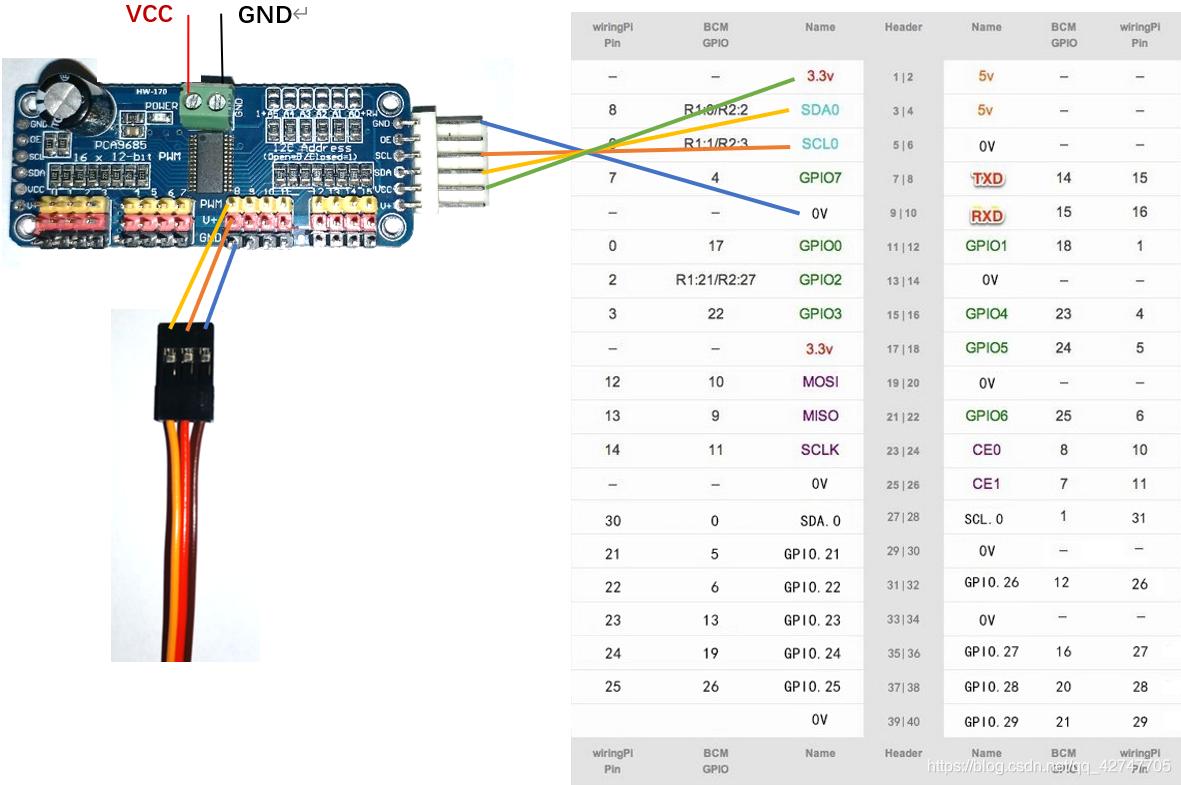
树莓派控制16路PWM输出的PCA9685模块 1.PCA9685 1.1简介 采用I2C通信,内置了PWM驱动器和一个时钟,不需要不断发送信号占用单片机资源 支持16路PWM输出,每路12位分辨率(...
安装了Python3.7之后,遇到的一个很麻烦的坑就是与系统自带的ssl版本不兼容, Python3.7需要的openssl的版本为1.0.2或者1.1.x,这个requirements在config...
前言 我觉得如果使用 python 开发的话,还是在 unix/linux 的环境下吧,shell 工具的效率比 windows 高得多,尽管 windows 下也有 cmder 这种神器,而且现在 ...
brew install mysql brew unlink mysql brew install mysql-connector-c sed -i -e ‘s/libs=”$libs -l...
1.关于Keras 1)简介 Keras是由纯python编写的基于theano/tensorflow的深度学习框架。 Keras是一个高层神经网络API,支持快速实验,能够把你的idea迅速转换为结...
一、为何要用Keras 如今在深度学习大火的时候,第三方工具也层出不穷,比较出名的有Tensorflow,Caffe,Theano,MXNet,在如此多的第三方框架中频繁的更换无疑是很低效的,只要你能...