

2025-06-17
2025-05-20
openwrt安装Mihomo
https://firmware-selector.openwrt.org/ 打开上面网址选择 Generic x86/64 版本, 定制openwrt时在后面增加: luci-i18n-base-z...
2025-05-12
树莓派改换源bookworm
deb [ arch=armhf ] http://mirrors.aliyun.com/debian bookworm main contrib non-free-firmware deb http...
2025-04-22
群晖安装iperf3
群晖NAS内网速度测试 SSH登录群晖NAS,并切换到管理员权限sudo -i 安装Diagnosis Tool,sudo synogear install 运行/var/packages/Diagn...
2025-03-17
停止windows自动更新
reg add HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsUpdate\UX\Settings /v FlightSettingsMaxPauseDay...
2024-09-19
树莓派编译 CH348 驱动的一点问题
CH348 芯片的主要功能和特点 高速传输:内置单片机高速 480Mbps USB 收发器和控制器。 单口高集:各串口内部置独立收发 FIFO,支持高达 6Mbps 波特率。 双电源设计:串口 IO ...
2024-09-18
python2.7安装mysql-python 报错没找到my_config.h
解决办法: 创建my_config.h文件 vim /usr/include/my_config.h1添加my_config.h内容 链接: 官网
2024-05-29
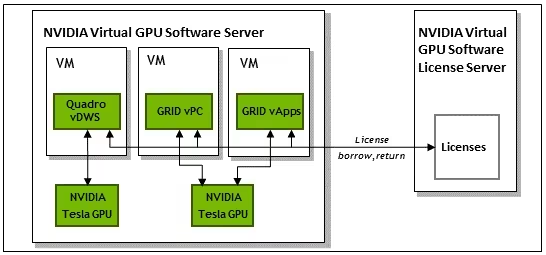
显卡虚拟化,Tesla P4在PVE8下的vgpu配置方案,兼容多显卡直通
前言 UP主最近买了一张Tesla P4的显卡,准备折腾一下显卡虚拟化。主要需求来自于我每天都会使用家里的几台虚拟机完成不同的工作任务。因为虚拟机没有显卡所以很多操作比较卡,用着不是那么顺手。也正因为...