

2024-05-29
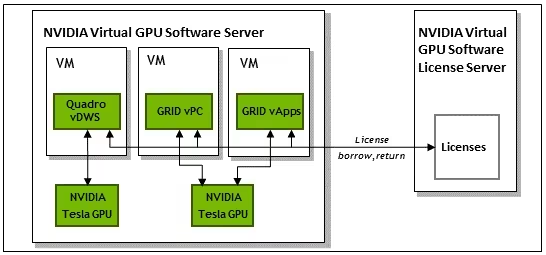
显卡虚拟化,Tesla P4在PVE8下的vgpu配置方案,兼容多显卡直通
前言 UP主最近买了一张Tesla P4的显卡,准备折腾一下显卡虚拟化。主要需求来自于我每天都会使用家里的几台虚拟机完成不同的工作任务。因为虚拟机没有显卡所以很多操作比较卡,用着不是那么顺手。也正因为...
逆水行舟, 不进则退!
前言 UP主最近买了一张Tesla P4的显卡,准备折腾一下显卡虚拟化。主要需求来自于我每天都会使用家里的几台虚拟机完成不同的工作任务。因为虚拟机没有显卡所以很多操作比较卡,用着不是那么顺手。也正因为...
下载 DELL idrac7 激活工具https://down.cnaaa.net/static/upload/other/20230217/1676619894923325.zip DELL 官方 ...
默认注释了源码镜像以提高 apt update 速度,如有需要可自行取消注释 deb https://mirrors.tuna.tsinghua.edu.cn/debian/ bookworm mai...
要将 iptables 配置为将全局流量转发到 Socks5,可以按照以下步骤进行操作。 首先确保已经安装了 iptables 工具。如果没有安装,可以使用以下命令来安装: sudo apt-get ...
前言 此前打算重建 OpenStack 集群,顺带想把机房的二十几台服务器从 CentOS 重装成 Ubuntu,这么多台机器一个一个插 U 盘接显示屏手动重装显然不太现实,正好借此机会研究一下 PX...
Ubuntu安装CUPS服务 本文以 Ubuntu 22.04 为例, 已使用 HP smart 安装打印机驱动并有线连接打印机. # 安装 apt install cups aptitude apt...
添加sata硬盘直通 qm set 100 -sata1 /dev/disk/by-id/ata-ST2000VX008-2E3164_Z52456RB qm set 100 -sata2 /dev/...
直接使用加速镜像:https://1ms.run/ sudo mkdir -p /etc/systemd/system/docker.service.d sudo vim /etc/systemd/s...
在【service】代码快最末尾加上TimeoutStartSec=2sec root@k8s-master1:~# cd /etc/systemd/system/network-online.tar...