

业务场景描述如下:
我有一个Nginx的web服务器,需要从统计日志中统计有哪些类型的设备终端和浏览器访问了我的网站。
访问日志中的每条记录是这样的:
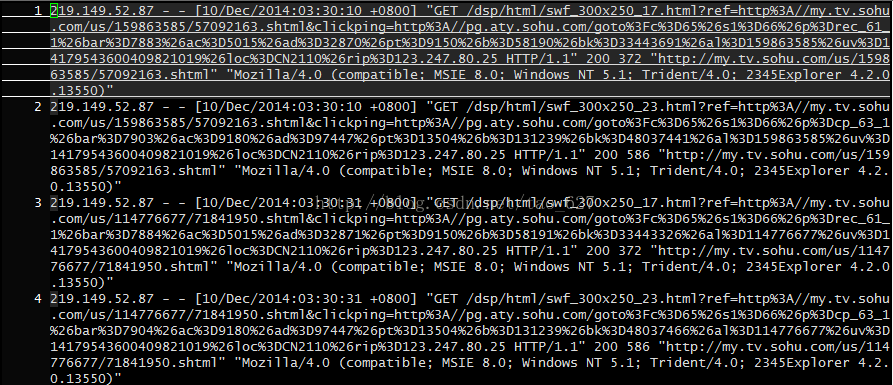
使用下面的命令得到user-agent所在的字段
cat cpm.access.log-20141211 | awk -F ‘”‘ ‘{print $6}’ > ua_1211.txt
意思是,处理该文件的每一行,指定“为分隔符,只输出第6个文本域
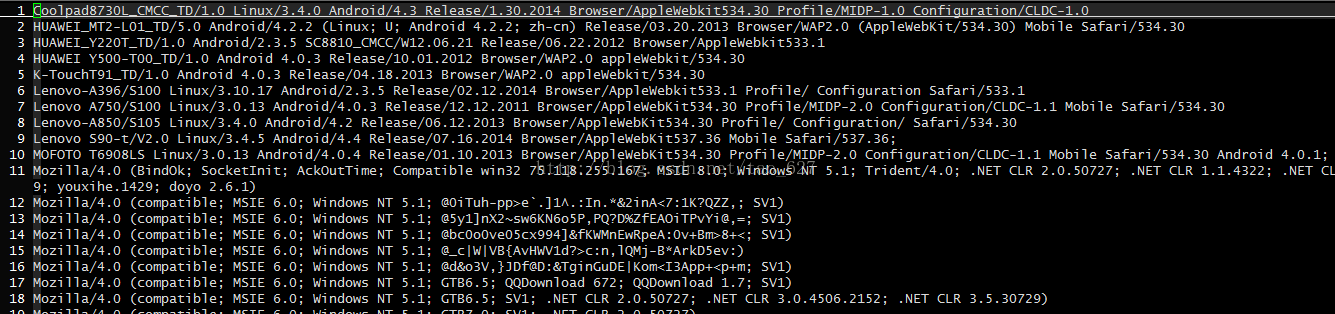
提取的user-agent字段得到的文件为
很显然,需要对这些行进行去重,这只需要一个简单的sort命令就可以请求搞定:
sort ua_1211.txt | uniq -u > ua_1211.sort.txt
对文档按照ascii字符顺序进行排序,同时去掉重复行,并将结果重定向到新文件中
下面是去重后的文件内容
为了结果更精确,我需要对当前目录下面的所有日志都做相同的分析,为此,我需要先将这些文件都合并到一个大日志文件中,再对这个大文件执行上面的操作。使用cat的通配符合并功能很容易实现文件合并:
cat cpm.access.log-2014121* > cpm.access.log
再对这个合并文件cpm.access.log做分析
cat cpm.access.log | awk -F ‘”‘ ‘{print $6}’ | sort | uniq -u > ua_analysis.txt
这次我们看到了更多神奇的东西,看来访问各种移动端访问我们网站还是很多的,总结有1333种终端访问。

其实类似的其他场景的问题也可以参照解决。
下面是我收集的user-agent文件,参见下载链接
观察日志发现UA字符串:
Mozilla/5.0 (compatible; Baiduspider/2.0; http://www.baidu.com/search/spider.html)
参考文献
[1].http://www.cnblogs.com/51linux/archive/2012/05/23/2515299.html
[2].http://www.cnblogs.com/ggjucheng/archive/2013/01/13/2858385.html